2-1-1. AI는 손글씨를 인식할 수 있을까?
●데이터 살펴보기
데이터 - MNIST(엠니스트) 데이터셋 사용
MNIST - 0부터 9까지 숫자를 손으로 그린 손글씨 데이터
총 7만 장 - 트레이닝 6만 장, 테스트 1만 장
가로세로 28 픽셀 크기의 이미지.
배경의 값은 0이며 숫자가 기재된 구역의 값은 255. 이번 절의 예제는 배경의 값을 0, 숫자가 기재된 구역의 값 을 1로 노멀라이즈하여 학습.
●어떤 인공지능 사용?
3층짜리 FNN
| 층수 | 종류 | 크기 | 활성화 함수 |
| 1층 | Flatten | 28 x 28 | 없음 |
| 2층 | FNN | 256 | ReLu |
| 3층 | FNN | 10 | SoftMax |
1층에 'Flatten' - flat은 '납작한' 이라는 뜻이며 Flatten은 '납작하게 만들다' 라는 의미
말 그대로 입력받은 데이터를 납작하게 만들어 주는 것
2층은 크기 256에 렐루를 활성화 함수로 평범한 신경망
3층은 총 10종류의 숫자를 분류하기 때문에 크기는 10, 활성화 함수는 SoftMax 사용
Flatten 레이어
이미지 파일은 x축, y축로 이루어진 데이터.
앞서 해왔던 것은 FNN에 1차원 데이터를 입력.
(성별, 키, 몸무게)/(꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 넓이)
이 처럼 2차원인 이미지 파일을 1차원으로 만들어 주는 역할이 Flatten 레이어
3x3 => 9x1 로 4x4 => 16x1 / 현재 하려는 이미지는 28x28 => 784x1
●딥러닝 코딩
Flatten() 함수에 입력하는 것은 input_shape에 입력하려는 이미지 데이터의 크기를 입력.
MNIST 이미지는 28x28 사이즈이므로 (28,28)을 입력.
옵티마이저(optimizer) - Adam
메트릭(metrics) - accuracy
로스(loss) - sparse_categorical_crossentropy
●인공지능 학습
인공신경망 학습
학습 결과 출력
그래프로 출력
●인공지능 학습 결과 확인
인공지능 성능 확인하기

저자의 경우 14에포크에서 멈추었고 정확도가 97.98%를 보임.
나같은 경우 15에포크에서 멈추었고 정확도가 98.01%를 보임
학습 기록 확인하기


빨간 선이 train, 파란 선이 test
저자의 경우, loss의 경우 트레이닝은 꾸준히 내려가지만 3에포크 이후 감소하지 않음 => 오버피팅 발생
accuracy의 경우 3에포크 이후 눈에 띄는 성능 향상을 딱히 없는 것으로 관찰 됨.다만 1에포크에서 이미 정확도가 97%가량 됨. 오버피팅 되었지만 꽤 괜찮은 성능의 인공지능을 만드는데 성공.
나의 경우, loss가 2에포크 이후 감소하다가 증가하는 구간도 있음 =>오버피팅이 심하게 발생 한거 같음.accuracy의 경우, 저자와 같이 1에포크에서 97%가량 되고 어느 정도 조금씩 증가함.
※
MNIST와 Fashion MNIST
MNIST는 미국의 NIST에서 제작한 데이터베이스.
이 기관의 약자 앞에 M을 붙여서 MNIST.
이 데이터셋은 손으로 작성한 숫자 데이터를 포함하고 있으며, 인공지능 학습에 용이하도록 데이터의 배경을 0, 글자 영역은 255로 노멀라이즈되어 있음.
데이터의 크기도 큰데 활용하기 편하게 가공까지 되어 있어 전 세계적인 인기를 누리게 되었음.
MNIST와 비슷한 데이터셋이 많은데 그 중 가장 유명한 것이 Fashion MNIST.
이 데이터는 패션 및 라이프스타일 제품 전자상거래 플랫폼인 Zalando사의 패션의류 데이터를 가공하여 제작한 데이터 셋.
상의, 하의, 가방, 부츠, 코트 등 총 10종류 카테고리의 의류 데이터를 수집하여 MNIST와 마찬가지로 28x28사이즈로 정리한 데이터.
드롭아웃
이번 예제의 결과는 오버피팅이 심하게 발생.
드롭아웃을 활용하면 오버피팅을 피할 수 있다고 배움.
실제로 그런지 확인.
(드롭아웃은 크기가 큰레이어에 적용할 때 더욱 효과적)

정확도가 조금 낮아진 느낌이 있지만

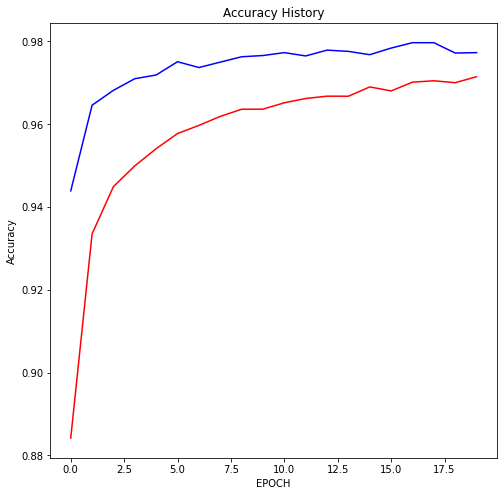
빨간 선이 train, 파란 선이 test
train보다 test가 그래프로 보면 loss는 더 낮아지고 accuracy의 경우 더 나은 경우를 보인다.
'@@@ 인공지능 > 수학·통계를 몰라도 이해할 수 있는 쉬운 딥러닝' 카테고리의 다른 글
| 2 - 1. 이미지 분류(Classification) 기법 활용하기(3) (0) | 2021.07.14 |
|---|---|
| 2 - 1. 이미지 분류(Classification) 기법 활용하기(2) (0) | 2021.07.14 |
| 2. 인간의 시각 처리를 흉내 낸 인공지능 - CNN (0) | 2021.07.07 |
| 1 - 4. FNN 활용하기(2) (0) | 2021.07.07 |
| 1 - 4. FNN 활용하기(1) (0) | 2021.07.06 |