키워드 : 통계적 가설, 귀무가설, 대립가설, 유의확률, 유의수준, t-검정, ANOVA
통계적 가설 : 통계학에서 사용하는 용어. 하나의 특정 주장을 모수를 이용해 나타낸 형태를 지칭.
귀무가설 : '차이가 없거나 의미있는 차이가 없다'를 기본 전제로 하는 가설.
대립가설 : '차이가 있다'고 보는 가설. 연구자가 입증되기를 기대하는 가설.
유의확률 : 실제로는 차이가 없는데 우연히 집단 간의 차이가 있는 데이터가 추출되었을 확률을 말함.
유의수준 : 유의확률값을 '크다' 또는 '작다'로 판단하는 기준.
t-검정 : 두 집단의 유의하게 차이가 있는 지를 판별할 때 표본의 평균값을 활용하는 검정.
ANOVA : 집단 간 차이를 검정하는 데 표본의 분산을 활용하는 검정.
1.4.1 통계적 가설
통계학에서 사용하는 용어. 하나의 특정 주장을 모수를 이용해 나타낸 형태를 지칭.
예를 들어, '성인 남성의 평균 신장은 170cm이다'와 같은 주장. 여기에서 평균 신장은 모집단 특성을 나타내는 모수의 역할.
통계적 가설은 귀무 가설과 반대에 있는 대립가설로 나타냄
1.4.1.1 귀무가설과 대립가설
데이터 분석은 종종 차이가 확실한지, 또는 차이가 나지 않는지가 궁금하여 실시하는 경우가 많음.
예를 들어, '특정 치료제가 효과가 있는가?' 에 대해서
치료제의 허가를 쉽게 내줄 수 없기 때문에 '치료제가 효과가 없다'는 가설을 우선시 한다. 이것이 귀무가설(null hypothesis, 기호 $H_0$) 또는 영가설.
귀무가설은 통계학에서 처음부터 버릴 것을 예상하는 가설. 차이가 없거나 의미있는 차이가 없는 경우의 가설.
귀무가설과 반대되는 가설을 대립가설(alternative hypothesis, 기호 $H_1$) 또는 연구가설.
대립가설은 연구자가 연구를 통해 입증되기를 기대하는 예상이나 주장하는 내용.
예시에서는 '특정 치료제가 효과가 있다'가 대립가설이 된다.
대립가설은 단측 대립가설과 양측 대립가설이 있음.
단측 대립가설 - 관련성을 검정할 때 그 방향이 미리 어느 한쪽으로 결정되어 있는 경우.
예시에서 '치료제가 효과가 좋은가?'라는 것을 밝혀낼 때에 더 효과가 좋다는 가설이 단측 대립가설.
일원(한쪽 꼬리) 가설 검정이라고도 함.
양측 대립가설 - 차이가 '존재하는가?'라는 면에서만 관심을 가지는 것이며 그 방향은 따지지 않는 가설.
예시에서는 '치료제 효과에 차이가 있다'라고 가정하는 것. 이 경우는 환자의 상태가 더 나빠지는 것도 포함.
이원(양쪽 꼬리) 가설 검정이라고도 함.
통계 분석에서 귀무가설 채택 시 대립가설은 기각, 귀무가설 기각 시 대립가설은 채택.
1.4.1.2 유의확률(Significance probability, p-value)
가설의 채택 또는 기각의 중요한 지표가 되는 p-value
p-value(p-값)라는 용어로 유명한 유의확률의 개념은 실제로는 차이가 없는데 '우연히 집단 간의 차이가 있는 데이터가 추출되었을 확률'을 말함.
분석 결과 유의확률이 크면 '집단 간 차이가 통계적으로 유의하지 않다'고 해석.
이 경우 귀무가설이 채택, 대립가설 기각.
예시에서는 치료제 효과는 '우연에 의해 차이가 관찰될 가능성이 크다'는 의미.
분석 결과 유의확률이 작으면 '집단 간 차이가 통계적으로 유의하다'고 해석.
이 경우 귀무가설이 기각, 대립가설 채택.
예시에서는 치료제 효과가 존재하고 그것이 '우연이라고 보기는 힘들다'는 의미.
분석 결과 유의확률 값을 '크다' 또는 '작다'로 판단하는 기준.
그 기준을 유의수준(significance level)이라고 부르며 다수의 통계학자가 유의수준을 0.05로 사용.
0.05보다 작은 유의확률이 구해질 경우 귀무가설을 기각. 하지만 절대적인 기준은 아님.
0.1 또는 0.01을 기준으로 사용하는 경우도 있음.
유의 수준은 보통 $\alpha$로 표기. 1-유의수준(1-$\alpha$)을 신뢰구간 또는 신뢰수준이라고 부름.
0.05가 유의수준이라면 95% 신뢰 수준을 기준으로 한다는 의미. 유의확률을 구하는 방법은 가설 검정마다 다름.
1.4.2 가설 검정
가설 검정은 모집단에 대한 가설을 설정한 후에 표본 관찰을 통해 그 가설의 채택 여부를 결정하는 분석 방법.
귀무가설과 대립가설 중에 하나를 선택하는 과정.
귀무가설이 옳다는 전제하에 p-value를 구한 후 유의수준보다 크면 귀무가설을 채택하고, 작으면 귀무가설을 기각한다.
1.4.2.1 t-검정(t-test)
두 집단이 유의하게 차이가 있는지를 판별할 때 표본의 평균값을 활용하는 검정.
관찰 대상 전체에 해당하는 모집단의 관측값을 수집하는 것은 불가능한 경우가 대다수이므로 표본을 추출하고, 그 표본의 평균을 이용하여 모집단 간 차이를 검증.
비교 대상이 되는 집단은 같은 집단일 수 있음.
예를 들어, 다이어트약의 효능을 검정할 때, 다이어트약 복용 전 몸무게를 관측한 집단과 약 복용 후 몸무게를 관측해야 하는 집단은 같은 집단의 표본이어야 함.
다이어트약 복용 후 몸무게가 약 복용 전 몸무게와 유의하게 차이가 나는지 t-검정을 수행할 수 있음.
이를 대응 이표본 t-검정(Dependent t-test for paired sample)이라고 함.
비교 대상의 집단이 다른 집단인 경우는 예를 들어, 서울의 남자 고등학생 몸무게와 부산의 남자 고등학생 몸무게가 유의하게 차이가 나는지 검정을 하고자 하는 경우.
이를 독립 이표본 t-검정(Independent two-sample t-test)라고 부름.
하나의 모집단에서 추출한 표본으로 모집단의 모수를 추정하기 위해 t-검정을 수행할 수 있음.
이것은 일표본 t-검정(One-sample)이라고 부름.
좀 더 쉽게 말해, 모집단의 평균과 표본의 평균을 비교.
예를 들어, 생산된 모든 맥주의 도수가 4.2% 이어야 하는 맥주 공장이 있다고 가정.
모든 맥주의 도수를 검사해 볼 수 없으니 일부 샘플의 맥주 도수를 검사하여 모집단의 맥주 도수에 문제가 없다는 것을 검정해야 함. '95% 신뢰구간에서 우리 공장의 맥주의 도수는 4.2%의 값으로 추정된다'처럼 결론을 얻기 위해 일표본 t-검정을 수행.
T-검정 종류 간단 설명
t-검정은 다음의 가정을 전제로 함.
| 두 모집단은 정규분포를 따른다. |
이 가정을 전제로 수행하는 t-검정의 과정.
1. t-value와 자유도(n-1)를 구한다. 여기에서 n의 표본의 수를 의미.
일표본 t-검정의 t-value 식
$$ t=\frac{\overline{X}-\mu}{S_{\overline{X}}} S_{\overline{X}} : 표본평균의 표준편차, \overline{X} : 표본평균, \mu : 기준값 $$
이표본 t-검정의 t-value 식
$$ t=\frac{\overline{X1}-\overline{X2}}{S_{\overline{X1}-\overline{X2}}} \overline{X1}-\overline{X2} : 두 표본의 그룹 평균의 차이, S_{\overline{X1}-\overline{X2}} : 두 그룹 간 평균 차이에 대한 불확실도 $$
2. 자유도(n-1)의 t-분포를 구한다.
t-분포란 차이가 없는 즉, 차이가 0인 두 모집단의 표본을 추출하여 평균의 차를 이용한 t-value의 분포.
여기에서 차이가 없는 두 모집단의 표본 평균의 차이는 당연히 모두 0 ?
평균 차이를 분자로 한 t-value 도 0. 모두 0 인데 분포를 구할 필요가 있을까?
하지만 실제로 t-value는 0이 아닌 경우도 있다.
여러번 표본을 뽑아 t-value를 구하면 0에 근접한 어떤 분포가 생기는데 이를 t-분포라고 한다.
t-분포와 t-value
다음은 t-분포의 확률밀도함수. $$f(t) = \frac{\Gamma(\frac{\nu+1}{2})}{\sqrt{\nu\pi}}(1+\frac{(t-\mu)^2}{\nu\sigma^2}^{-\frac{=nu+1}{2}}$$
식을 이해하기보다는 t-분포를 구하는식에서 자유도(n-1)가 t-분포를 결정하는 모수가 된다는 것을 기억.
t-분포의 확률밀도함수 식에서 $\nu$는 자유도 즉, 표본수(n) - 1을 의미.
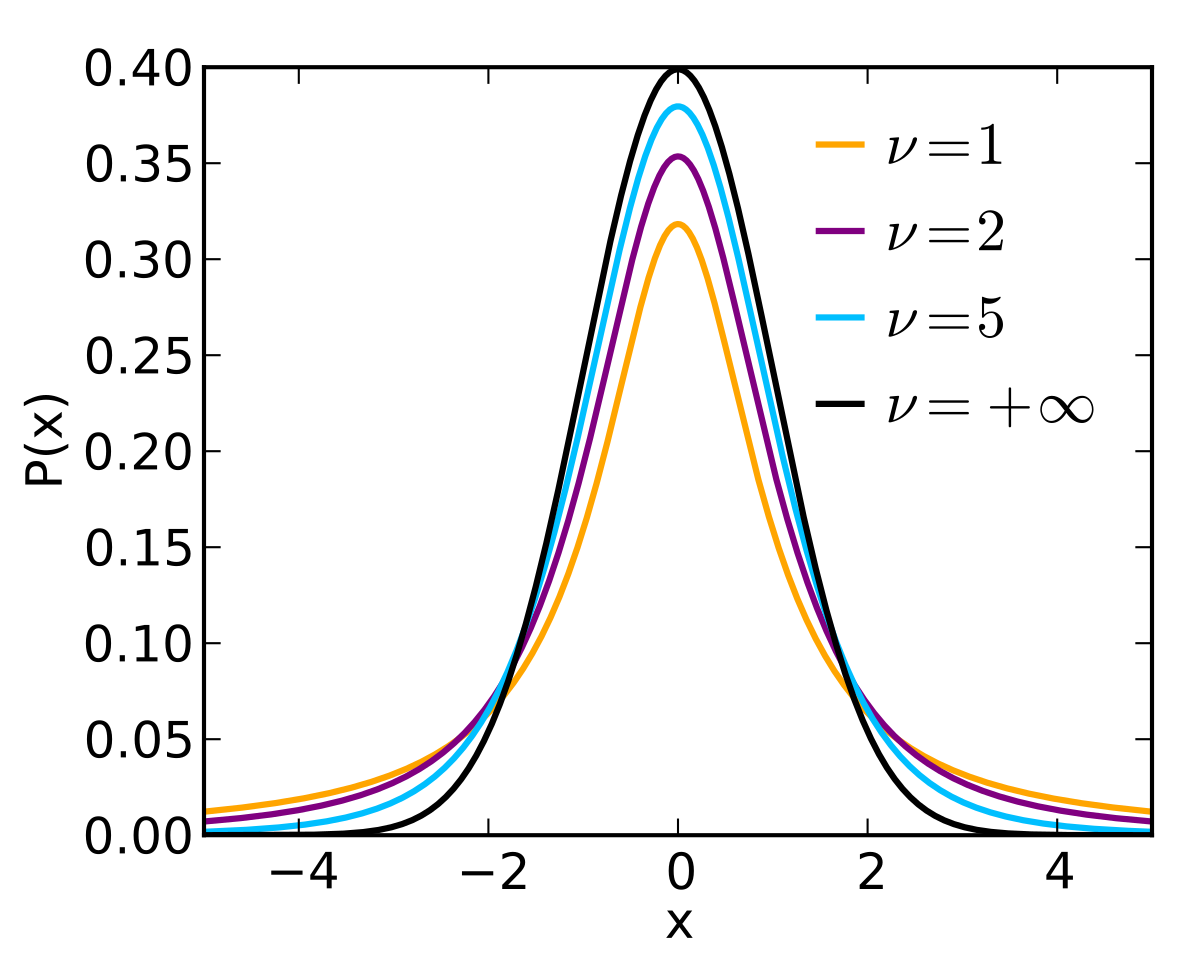
t-분포는 다이어트약을 복용하지 않은 모집단에서 일부 샘플을 뽑아 한달 전, 후 몸무게의 차이를 평균내어 분포로 나타낸 것이라고 가정할 때, '평균적으로 몸무게 차이가 0이었지만 몸무게가 늘어난 사람도 있고, 줄어든 사람도 있었다'는 것을 설명하는 분포.
3. t-분포에서 t-value의 위치를 찾아 p-value를 계산.
예를 들어 다이어트약을 복용하고 한 달 후, 몸무게를 다시 측정하고 1. 에서 나온 식으로 복용 전후 몸무게로 t-value를 구하고 2.에서 구한 t-분포에서의 위치를 찾아 p-value를 계산. 이때, p-value가 0.02이라고 가정하면 다이어트약을 먹지 않은 사람들 중 2%에서만 몸무게 변화가 발생했다고 말할 수 있음. 이것은 2. 에서 구한 t-분포가 다이어트약을 복용하지 않은 사람들의 한 달 후 몸무게 변화에 대한 분포이기 때문.
4. p-value를 유의수준(0.05)와 비교.
유의수준이 0.05라면 5%를 기준으로 하여 특이케이스로 판단한다는 의미.
즉, 이 사례에서처럼 p-value가 0.02이라면 다이어트약을 먹지 않은 사람들 중 2%에만 발생하는 즉, 98%에는 발생하지 않는 케이스로 판단.
즉, 다이어트 복용하지 않은 자연스러운 체중 감소 현상이라고 보기 어려우므로 이 다이어트약은 효능이 있다고 말할 수 있음. p-value가 0.02로 유의수준 0.05보다 작으므로 귀무가설은 기각되고, 대립가설이 채택.
예에서의 가설 검정을 정리하면
| 귀무가설 : 다이어트약은 효능이 없다. 즉, 다이어트약 복용 전 후 몸무게가 감소하지 않는다. 대립가설 : 다이어트약은 효능이 있다. 즉, 다이어트약 복용 한 달 후 몸무게가 감소한다. |
t-검정 과정이 매우 복잡해 보이나 걱정할 필요는 없음.
원리와 용어 정도만 기억한다면 R의 t.test()를 이용해서 간단히 t-검정을 수행할 수 있음.
1.4.2.2 ANOVA(분산 분석, analysis of variance)
집단 간 차이를 검정하는데 표본의 분산을 활용하는 검정.
분산을 활용하기 때문에 분산분석이라고 부름.
집단의 평균이 다르다는 말은, 각 집단의 평균이 떨어져 있다는 것, 즉 집단 간 분산이 크다는 것을 의미.
보통 집단 간 분산이 클 수록 그래프의 간격이 넓지만
분산분석은 집단 간 분산 외에 집단 내의 분산도 검정에 활용. 집단 간 분산이 크더라도 집단 내의 분산도 크다면 두 집단의 분포가 명확히 구분되지 않아서 평균이 다르다고 주장하기 어려울 수 있음.
집단 내 분산이 클 경우 종모양이 넓어지기 때문에 겹치는 부분이 많아지기 때문.
예를 들어, 어떤 수업을 받은 A와 아닌 B 두 집단의 성적을 비교했을 때, A가 평균이 더 높을 때, 수업이 효과가 있는가?를 알아보고자 할 때, 평균차이가 크다면 그렇다고 볼 수 있지만 평균차이가 작고, 학생간 차이가 크다면 개인차로 인해 다음과 같은 결과가 나왔을 수 도 있다.
즉, 두 반의 평균 차이가 크고(집단 간 분산이 크고), 각 반의 학생들의 점수 분산이 적을수록(집단 내 분산이 적을수록) 온라인 교육이 효과가 있었다고 말할 수 있음.
집단 간 분산이 클수록, 집단 내 분산이 작을수록 집단 평균이 유의하게 다를 가능성이 증가. 집단 간 분산과 집단 내 분산의 비를 f-value(f 통계량)라고 하고 이를 f-검정에서 활용.
$$ f-value = "frac{\text{집단 간 분산}}{\text{집단 내 분산}} $$
분산분석의 기본 가정.
| - 가정 1 : 각 집단에 해당되는 모집단의 분포가 정규분포. - 가정 2 : 각 집단에 해당되는 모집단의 분산이 같음. - 가정 3 : 각 모집단 내에서의 오차나 모집단 간의 오차는 서로 독립적. |
세 가지 가정을 충족시키기 위해서는 각 관측값이 독립적으로 뽑혀야 하며 각 모집단의 분산은 같고 정규분포를 이루어야 함.
f-검정은 다음과 같은 과정.
| 1. f-value와 자유도(n-1)를 구함. 여기에서 n은 표본의 수를 의미. 2. 자유도(n-1)의 f-분포에서 f-value의 위치를 찾아 p-value를 계산. 3. p-value의 값을 유의수준(0.05)과 비교. |
1.4.2.3 가설 검정의 결과와 오류
귀무가설($H_0$)이 사실인데 귀무가설을 기각했을 때의 오류를 '1종 오류'
반대로 대립가설($H_1$)이 사실인데 귀무가설을 채택했을 때의 오류를 '2종 오류'
| "True State" of the World | |||
| 귀무가설 $H_0$ is True | 귀무가설 $H_1$ is True | ||
| Decision | 귀무가설 ($H_0$)기각 | Type 1 Error(1종 오류) | Correct Decision |
| 귀무가설 ($H_0$)채택 | Correct Decision | Type 2 Error(2종 오류) | |
'@@@ 데이터분석 > 데이터 분석의 모든 것' 카테고리의 다른 글
| Chapter 2. R 프로그래밍 - 2.3 데이터 구조 (0) | 2021.09.12 |
|---|---|
| Chapter 2. R 프로그래밍 - 2.2 변수와 데이터 타입 (0) | 2021.09.12 |
| Chapter 1. 기초 통계 - 1.3 정규분포와 표준화 (0) | 2021.09.08 |
| Chapter 1. 기초 통계 - 1.2 기초 통계량과 확률 (0) | 2021.09.08 |
| Chapter 1. 기초 통계 - 1.1 통계 개요 (0) | 2021.09.06 |