Titanic - Machine Learning from Disaster | Kaggle
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
일단 필사를 위주로 다시 시작해보기
타이타닉 튜토리얼 1 - Exploratory data analysis, visualization, machine learning (tistory.com)
타이타닉 튜토리얼 1 - Exploratory data analysis, visualization, machine learning
My_kernel_chapter_data_check_EDA /*!** Twitter Bootstrap**//*! * Bootstrap v3.3.7 (http://getbootstrap.com) * Copyright 2011-2016 Twitter, Inc. * Licensed under MIT (https://github.com/twbs/bootstrap/blob/master/LICENSE) *//*! normalize.css v3.0.3 | MIT Li
kaggle-kr.tistory.com
캐글내에 자체 커널이 있어 데이터 사용 및 제출이 용이하다.
순서는
- Setting
- DataSet 확인
- EDA (탐색적 데이터 분석)
- Feature engineering (데이터 정제)
- Model 생성
- Model 학습 및 예측
- Model 평가
# 1 Setting
먼저 세팅하면서 사용할 라이브러리를 불러온다.
가장 많이 사용하는 것이 numpy, pandas, sklearn 이고 시각화를 위한 matplotlib, seaborn 을 주로 사용하는것 같다.

# 2 DataSet 확인
pandas의 read_csv로 csv 파일을 불러올 수 있다.

DataSet을 확인할 때는 describe, info를 주로 사용하고 describe의 파라미터로 include="all" 을 사용하여 전체를 다 볼 수 있다. 없다면 숫자와 관련된 feature만 나온다.



## null data 확인
null 값이 있으면 삭제, 대체 등과 같은 방법으로 해결을 해줘야 분석이 가능하다.
이러한 null 값을 찾는 방법은 위의 describe, info로도 확인이 가능하고 isnull과 같은 메소드로도 확인이 가능하다.
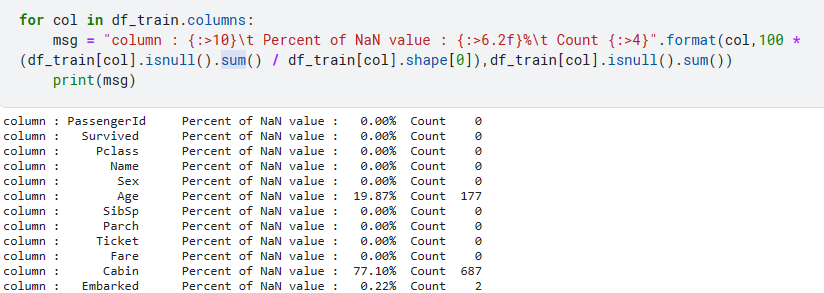
확인하고 싶은 col에 isnull을 붙여 확인가능하다.

하지만 이렇게 확인할때는 전체 데이터를 다 확인하긴 어렵기 때문에 뒤에 sum() 메소드를 붙여 합계로 파악하는 것이 쉽다.

이런식의 for문으로 한번에 확인가능
또한 missingno 라는 라이브러리를 통해 null 값을 쉽게 파악 할 수도 있다.


## Target Label 확인
Target Label 즉, 우리가 예측하고 싶은 Label의 분포를 확인해야 한다.
분포에 따라 데이터 처리를 해야하고 평가도 달라지기 때문.

# 3 EDA (탐색적 데이터 분석)
이제 본격적인 데이터 분석의 시작
다양한 통계 자료와 시각화를 통해서 데이터를 분석을 해야한다.
이때 많이 쓰는 것이 matplotlib, seaborn, plotly 등이 있다고 한다.
이제 각 feature들을 확인해볼 것이다.
Target과의 관계나 어떤 타입의 데이터인지 어떤 통계값을 가지는지 확인하고 활용해볼것입니다.
## Pclass
해당 데이터의 타입은 서수데이터 즉 순서가 있는 데이터이다.
이런한 서수데이터는 각각 몇개씩 데이터가 분포해있는지 파악을 해보고 Target과 관계를 확인하기 위해 Pclass에 따라 target의 분포를 확인해 볼 수있다.


이를 한번에 쉽게 할 수 있는 것이 pandas의 crosstab이 있다.

mean을 통해서 클래스별 생존률을 알 수 있음.
이렇게 확인하였을 때, 클래스가 높을수록 높은 것을 확인 할 수 있음.

seaborn의 countplot을 사용하여 즉정 label에 따른 개수를 확인 가능

앞선 결과들을 통해서 Pclass는 Survived와 관련이 있을 것이라고 판단이 되고 모델 생성시 사용할 것으로 판단.
## Sex


비슷하게 Sex의 경우에도 해봤을 때, 연관이 있다고 판단이 되어진다.
## Both Sex and Pclass
이번에는 2가지를 한번에 비교해보자
그림에서 보듯이 Sex와 Pclass가 독립적으로 작용을 한다.
각 Pclass에서 female이 높고 sex에 상관없이 Pclass가 높을수록 생존률이 높다.


## Age
이렇게 여러가지 통계를 통해 age에 대한 정보를 파악한다.
어릴수록 생존률이 높은걸 볼 수 있다.




## Pclass, Sex, Age
다 같이 보는 방법 violin 차트로 이렇게 봐도 여자의 생존률이 높다.
그리고 Pclass가 높을수록 생존률도 높다.
나이는 어릴수록 높다.

## Embarked
큰 영향은 없는 것으로 보인다.
삭제를 해도 될 것으로 확인이 되어진다.


## Family - SibSp(형제 자매) + Parch(부모, 자녀)
형제자매, 부모자녀 feature를 합치는 것이 좋지 않을까란 생각.
가족의 수가 2~4명일 때, 생존률이 높은 것을 확인 할 수 있다.


# Fare
딱 봐도 왜도가 엄청 높은 걸 볼 수 있다.
이를 위해 변환을 해줘야할듯 싶다. 그래서 생각한 것이 log변환과 역수변환.



역수 변환이 왜도는 더 낮게 나오지만 성능은 더 안좋은 것으로 판단된다.
## Cabin
Cabin은 결측치가 너무 많아 제거하는 것이 좋을 듯.

## Ticket
Ticket의 경우 다 다르고 string 이기 때문에 정확하게 파악해보고 특징점을 찾아서 활용하던가 제거하는게 좋아 보임.

'@@@ 데이터분석 > Kaggle' 카테고리의 다른 글
| [Kaggle] XGBoost 알아보기 (0) | 2023.01.05 |
|---|---|
| [Kaggle] Titanic 성능 향상(23.01.04) (0) | 2023.01.04 |
| [Kaggle] Titanic 연습해보기 (1) | 2022.12.30 |
| [Kaggle] Kaggel 자주 사용하는 함수 (0) | 2022.12.27 |
| [Kaggle] 분류 문제 - Titanic - Machine Learning from Disaster (2) (0) | 2022.12.26 |